When Not to Fine-Tune: The Cheaper Things to Try First
Series: Practical PyTorch · II (Phase II) — Part 8 of 9
We just spent several posts teaching you to fine-tune: transfer learning, the Trainer, evaluation, LoRA. You can do it now. So here’s the post that argues you usually shouldn’t — at least not first. Fine-tuning is the most powerful, most expensive, and most error-prone tool in the box, and reaching for it on day one is like rebuilding an engine because the car felt a little slow. There’s a good chance the thing you actually want is reachable without training anything at all.
This is the honest counterweight to the last few posts. The skill that pays off isn’t “can you fine-tune” — it’s knowing when to and, more often, when not to.
Open the companion notebook in ColabThe urge, and why to resist it
Fine-tuning feels like the serious answer. The model is wrong about your problem, so you’ll teach it — train it on your data until it gets things right. It’s satisfying and it sounds rigorous.
But sit with what fine-tuning actually requires before you commit. You need a labeled dataset, which usually means humans producing hundreds or thousands of examples. You need compute and a training run that can quietly fail in a dozen subtle ways. You need an evaluation set, or you won’t even know whether it worked. And you need to do it again every time a better base model ships — which, lately, is roughly monthly. That’s a real ongoing cost, not a one-time tax.
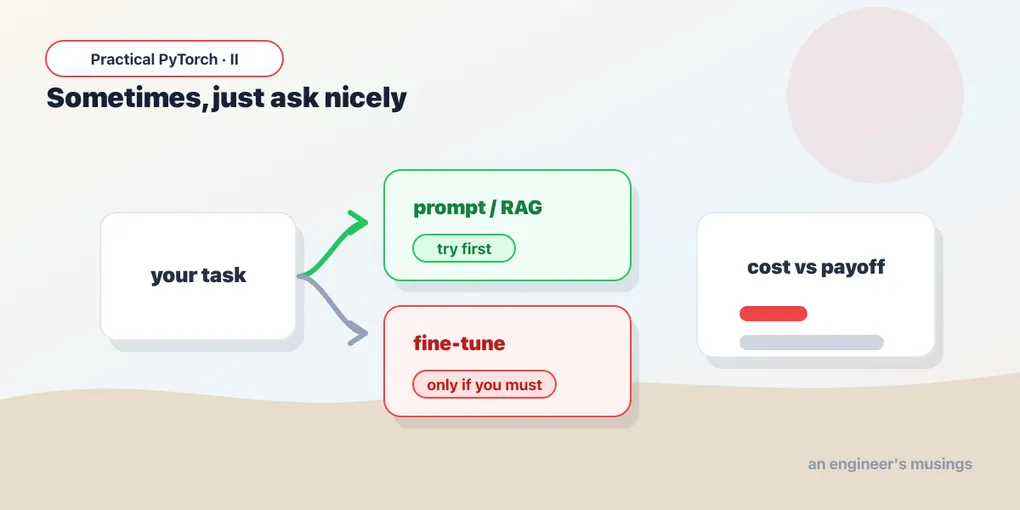
So the right instinct is to climb a ladder of cheaper options first, and only fine-tune when the cheaper rungs genuinely run out. This is especially true for large language models, where three alternatives cover a surprising amount of ground.
Option 1: Better prompting and few-shot examples
The cheapest fix is almost always the prompt. Modern LLMs are startlingly good at following instructions and at imitating examples you put right in front of them — and “putting examples in front of them” is most of what people think they need fine-tuning for.
If you want a specific output format, show it. Instead of training a model to always answer in JSON, give it two or three examples in the prompt and it’ll follow the pattern. This is few-shot prompting, and it’s the single highest-leverage trick in the kit:
prompt = """Classify each support ticket as BILLING, BUG, or FEATURE.
Ticket: "I was charged twice this month."
Label: BILLING
Ticket: "The export button does nothing when I click it."
Label: BUG
Ticket: "Could you add dark mode?"
Label: FEATURE
Ticket: "My invoice shows the wrong amount."
Label:"""You’ve just specified the task, the label set, and the output shape — without a training run, a dataset, or a GPU. The model reads the pattern and continues it. For a huge number of classification, extraction, and reformatting jobs, a few good examples in the prompt match what people expected fine-tuning to give them, at zero training cost and with a change you can edit in ten seconds.
The honest part: prompting has a ceiling. A prompt can only hold so many examples, and very long prompts get slower and pricier per call. But you should hit that ceiling before you conclude prompting isn’t enough — most people give up at the first mediocre result, not the actual limit.
Option 2: RAG, when the problem is missing knowledge
Sometimes prompting fails for a specific reason: the model simply doesn’t know the thing. It can’t summarize your internal wiki, answer questions about last quarter’s numbers, or cite your product docs — because none of that was in its training data, and no amount of clever phrasing conjures facts it never saw.
The instinct here is “fine-tune it on our documents.” Usually wrong. Fine-tuning is a clumsy, lossy way to stuff facts into a model, and the facts go stale the moment a doc changes. The right tool is RAG — retrieval-augmented generation — and the idea is simpler than the acronym:
When the model is missing facts, don’t bake them in. Look them up at question time and paste them into the prompt.
The flow has two steps. First, retrieve: take the user’s question, search your collection of documents for the most relevant chunks. Second, generate: hand those chunks to the model along with the question, and ask it to answer using the provided text. The model was always capable of reasoning over facts — it just needed the facts in front of it.
# Sketch of the idea — not a full implementation.
def answer(question, documents):
# 1. RETRIEVE: find the chunks most relevant to the question.
relevant = search(documents, question, top_k=3)
# 2. GENERATE: give the model those chunks and ask it to answer.
prompt = f"""Answer using only the context below.
Context:
{relevant}
Question: {question}
Answer:"""
return llm(prompt)That search step is the only genuinely new machinery, and it’s usually a vector search — documents and the question get turned into embeddings (numeric fingerprints of meaning), and you grab the chunks whose fingerprints sit closest to the question’s. Off-the-shelf libraries handle this; you rarely build it yourself.
RAG wins on the things fine-tuning is bad at. Facts update the instant you change a document — no retraining. Answers can cite their sources, which matters enormously for trust. And it generalizes to documents the model has never seen. If your problem is “the model doesn’t know my stuff,” reach for RAG long before fine-tuning. Fine-tuning teaches a model new skills and behaviors; RAG gives it new knowledge. Confusing the two is the most common expensive mistake in this whole area.
Option 3: Just use a better model
The least glamorous option, and frequently the best: try a bigger or newer off-the-shelf model before training a smaller one.
Teams spend weeks fine-tuning a small model to claw its way up to mediocre, when swapping in a stronger model would have cleared the bar on the first call — no dataset, no training, no maintenance. Base models improve fast, and a capability that was out of reach last year is often just a model-name change away today. Before you build anything, spend an afternoon seeing whether a more capable model simply solves the problem. It’s the cheapest experiment you’ll run, and it surprisingly often ends the project.
When fine-tuning genuinely is the right tool
None of this means fine-tuning is obsolete — it means it’s a specialist. Three cases where it earns its keep:
- Enforcing a consistent format, style, or behavior. When you need the model to respond a specific way every single time — a house tone, a rigid output structure, a refusal policy — and prompting gets you most of the way but not reliably enough. Fine-tuning bakes the behavior in so you’re not re-specifying it on every call. This is teaching a skill, which is what fine-tuning is actually for.
- A narrow, high-volume task where small beats big. If you’re running the same simple task millions of times, a tiny fine-tuned model that nails just that task can crush a giant general model on cost and latency. Spending real money to fine-tune a small model is a sound trade when it shrinks every inference bill thereafter.
- Domain adaptation when prompting plateaus. Genuinely specialized domains — legal, medical, a dialect of code — where you’ve pushed prompting and RAG to their limits and the model still doesn’t speak the language. When you’ve honestly exhausted the cheaper rungs, fine-tuning is the next move.
The thread tying these together: fine-tune to change how the model behaves, not to tell it facts. Facts are RAG’s job. Behavior is fine-tuning’s.
The real costs, stated plainly
Before you commit, price in the full bill — not just the training run:
- Labeled data. The hidden boss. Quality examples usually mean human effort, and “we’ll just label some data” routinely balloons into the longest part of the project.
- Compute and a working pipeline. A training run that can fail quietly — a bad learning rate, a leaky split, a subtle data bug — and cost you days before you notice.
- Evaluation. Without a held-out test set you can’t tell improvement from regression. If you skipped Part 6, this is your reminder that fine-tuning without evaluation is just expensive guessing.
- Maintenance. The one people forget. Base models keep improving, and a model you fine-tuned six months ago may already be worse than today’s off-the-shelf option. You’re signing up to redo this, possibly soon.
The decision checklist
When you’re tempted to fine-tune, walk down the ladder first and stop at the first rung that works:
- Try better prompting. Clearer instructions, a few-shot example or three. Push this further than feels necessary.
- Try RAG — if the problem is missing knowledge rather than missing skill. Retrieve the facts, paste them in, let the model reason.
- Try a bigger or newer model. Cheapest experiment in the building; often ends the project.
- Then fine-tune — for consistent behavior, a narrow high-volume task, or a domain where you’ve truly hit the wall. With eyes open about the data, compute, evaluation, and upkeep it commits you to.
If you can’t articulate which rung failed and why, you’re not ready for the next one.
Gotchas
- Fine-tuning teaches behavior, not facts. The deepest confusion in the field. Training a model on your documents to make it “know” them is using the wrong tool — that’s RAG. Reach for fine-tuning to change how it responds, not what it knows.
- Most “we need fine-tuning” cases are bad prompts. Before concluding the model can’t do something, check whether you actually asked clearly and showed an example. The number of fine-tuning projects that a better prompt would have killed is genuinely large.
- Fine-tuning bakes in stale knowledge. Whatever facts you train in are frozen at training time. Your data changes; the model doesn’t notice until you retrain. RAG sidesteps this entirely.
- No eval set, no fine-tuning. If you can’t measure whether the fine-tune helped, don’t start. You’ll have no idea whether you improved the model or quietly broke it.
- Small fine-tuned models can beat big ones — on narrow tasks only. This is a real win, but it’s specifically for repetitive, well-scoped jobs at high volume. Don’t generalize it into “fine-tuning beats big models,” which is false in the open-ended case.
- Yesterday’s fine-tune can be worse than today’s base model. Base models move fast. Budget for the possibility that your hard-won fine-tune gets lapped by a model-name change, and re-check periodically.
What’s next
You now have the most underrated skill in applied machine learning: knowing when not to train. Prompting, RAG, and a better base model clear most problems faster and cheaper than fine-tuning, and the pros reach for them first — fine-tuning is the specialist tool you deploy when you’ve earned the right to.
But sometimes you’ve climbed the whole ladder and fine-tuning really is the answer. So let’s put the entire series together and actually ship one.
Next: Part 9 — Capstone: Fine-Tune and Ship, where we take everything from Phase II and turn it into a working, shareable thing.
Target keyword(s): when to fine-tune vs prompting vs RAG, when not to fine-tune, fine-tuning alternatives.
Comments