Sampling and Elicitation: When the Server Asks Back
MCP isn't one-way. A server can ask the host's model to complete a prompt (sampling) and ask the user for structured input mid-task (elicitation). How both work, in Python and TypeScript.
Series: Building MCP Servers — Part 6 of 12
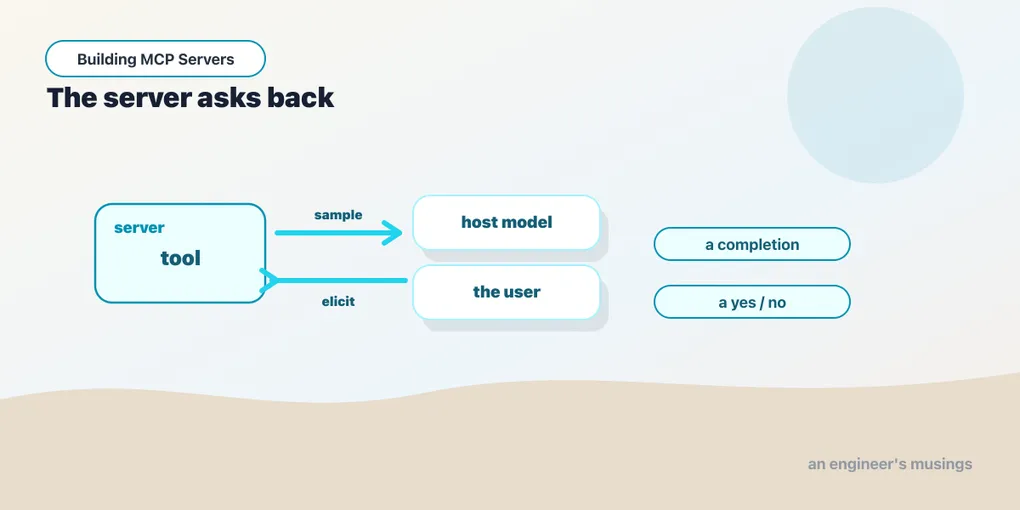
The first five posts were all one direction: the server offers tools, resources, and prompts; the host reaches in and uses them. But MCP is bidirectional. Inside a tool, your server can turn around and ask the client for two things — a model completion (sampling) and structured input from the user (elicitation). Both unlock patterns that are awkward or impossible otherwise, and both come with a catch worth understanding before you lean on them.
Sampling: borrow the host’s model
Say your tool needs to summarize, classify, or rephrase something — work a language model is good at. The naive move is to embed your own LLM call, which means your server ships an API key, picks a model, and pays the bill. Sampling flips that around: your server asks the host to run the completion, on the model the host already has.
from mcp.server.fastmcp import Context, FastMCP
from mcp.types import SamplingMessage, TextContent
@mcp.tool()
async def summarize(text: str, ctx: Context) -> str:
"""Summarize text by asking the host's model to do it."""
result = await ctx.session.create_message(
messages=[
SamplingMessage(
role="user",
content=TextContent(type="text", text=f"Summarize in one line: {text}"),
)
],
max_tokens=100,
)
return result.content.text if result.content.type == "text" else "(non-text)"server.registerTool(
"summarize",
{ title: "Summarize", description: "…", inputSchema: { text: z.string() } },
async ({ text }) => {
const result = await server.server.createMessage({
messages: [
{ role: "user", content: { type: "text", text: `Summarize in one line: ${text}` } },
],
maxTokens: 100,
});
const out = result.content.type === "text" ? result.content.text : "(non-text)";
return { content: [{ type: "text", text: out }] };
}
);The tool asks for a completion and gets one back, without ever knowing which model produced it. That’s the elegance: your server stays model-agnostic and key-free, and the host keeps control. The host also keeps the user in control. A well-behaved client can show the request for approval before it runs, and let the user see the result before it’s returned. Your server proposes; the host disposes.
Elicitation: ask the user, mid-task
Sometimes a tool can’t proceed without information it doesn’t have — and the model shouldn’t invent it. Think of a confirmation before something destructive, a missing parameter, a choice between options. Elicitation lets the server pause and ask the user a structured question, then continue with the answer.
from pydantic import BaseModel, Field
class Confirm(BaseModel):
confirmed: bool = Field(description="Type true to proceed")
@mcp.tool()
async def delete_everything(ctx: Context) -> str:
"""Ask the user to confirm, then act."""
result = await ctx.elicit(message="Really delete everything?", schema=Confirm)
if result.action == "accept" and result.data and result.data.confirmed:
return "deleted"
return "cancelled"async () => {
const result = await server.server.elicitInput({
message: "Really delete everything?",
requestedSchema: {
type: "object",
properties: { confirmed: { type: "boolean", description: "Check to proceed" } },
required: ["confirmed"],
},
});
const ok = result.action === "accept" && result.content?.confirmed === true;
return { content: [{ type: "text", text: ok ? "deleted" : "cancelled" }] };
}You hand elicitation a message and a schema for the answer. The host renders a form, the user fills it (or doesn’t), and you get a result back with an action. Don’t skip that action: it’s accept, decline, or cancel, and only accept carries data. A user who closes the dialog hasn’t said “yes” — treat anything but accept as “do not proceed.” The code above does exactly that, which is why declining the prompt returns cancelled rather than charging ahead.
The catch: capabilities
Both of these are requests to the client, so they only work if the client supports them. Clients announce what they can do during the initial handshake. A server that calls create_message against a client without sampling support gets an error, not a completion. In production, treat sampling and elicitation as features you degrade gracefully around. Check that the client offers them, and have a fallback when it doesn’t. A tool that summarizes via sampling might accept a pre-written summary argument instead. The whole exchange is verifiable today. Point a client that implements the sampling and elicitation callbacks at these tools, and the round trips complete — which is exactly what Part 9 builds.
Final thoughts
Sampling and elicitation are what make a server feel like a participant rather than a vending machine. Take a tool that can ask the model to do the fuzzy part, or stop and check with a human before the dangerous part. It’s a fundamentally more capable thing than one that can only take arguments and return values. Reach for them deliberately; they add a dependency on client support. But when the task needs a conversation, this is how the server joins it.
Next: Going Remote: The Streamable HTTP Transport, where the server stops being a local subprocess and starts being a service.
Target keyword(s): mcp sampling, mcp elicitation.
Comments