Misk Job Queues: Transactional, SQS-Backed Background Work
How the misk job queue works: defining handlers, enqueuing, and the misk sqs (misk-aws2-sqs) backend — plus the transactional spooling table and its exactly-once-ish guarantee.
Series: Building Production Services with Misk — Part 18 of 24
Some work has no business happening inside a request. Sending the receipt email, re-indexing the search document, fanning out a webhook — the caller doesn’t need to wait for it, and you don’t want a flaky SMTP server turning a 200 into a 500. You want to hand the work off and return. The misk job queue is Misk’s answer: a small, queue-agnostic API for enqueuing and consuming background jobs, with a production backend on Amazon SQS. The interface is deliberately boring, the SQS implementation does the hard parts, and there’s a real story for the one question that actually matters — what happens when a job is enqueued but the database transaction that triggered it rolls back. Let’s wire it.
The job queue is at-least-once, and says so
Before any code, internalize the contract, because it dictates how you write every handler. Misk’s JobHandler interface documents it in the source itself: “The jobqueue framework assumes that the underlying queueing system is at-least-once, so handlers must be prepared for the possibility that a job will be delivered more than once.”
That’s not a Misk limitation — it’s SQS being honest. A job can be delivered twice — if your process dies after handling but before acknowledging, or if processing outruns the visibility timeout — so the framework refuses to pretend otherwise. Every handler you write must be idempotent, or must dedupe on something. This is the single most important sentence in this post, and the rest of the design follows from it.
The good news — Misk gives you a per-job idempotenceKey to dedupe against, and a path that makes deduping a database operation rather than a prayer. We’ll get there.
Defining a job handler and enqueuing
There are two generations of the API in the tree. The modern one — used by the SQS backend you’ll actually deploy — lives in misk.jobqueue.v2. A handler implements one of two interfaces and returns a status instead of calling methods on the job:
package misk.jobqueue.v2
sealed interface JobHandler
interface BlockingJobHandler : JobHandler {
fun handleJob(job: Job): JobStatus
}
interface SuspendingJobHandler : JobHandler {
suspend fun handleJob(job: Job): JobStatus
}The returned JobStatus tells the framework what to do next, and it’s a closed set of exactly four outcomes:
enum class JobStatus {
OK, // processed; delete from the queue
RETRY_LATER, // make visible again, retry on the queue's schedule
DEAD_LETTER, // give up, route to the dead-letter queue
RETRY_WITH_BACKOFF, // retry, but back off the visibility timeout
}This is a genuine improvement over the older generation — where handlers had to call job.acknowledge() / job.deadLetter() themselves and could forget to. Now you return a value and the framework does the acknowledgement. A handler reads the job and decides:
@Singleton
class SendReceiptHandler @Inject constructor(
private val mailer: Mailer,
private val receipts: ReceiptStore,
) : BlockingJobHandler {
override fun handleJob(job: Job): JobStatus {
val receiptId = job.body // body is an arbitrary String; you pick the encoding
if (receipts.alreadySent(receiptId)) return JobStatus.OK // idempotent: dedupe
return try {
mailer.sendReceipt(receiptId)
receipts.markSent(receiptId)
JobStatus.OK
} catch (e: TransientMailError) {
JobStatus.RETRY_WITH_BACKOFF
}
}
}The Job itself is intentionally thin — a queue name, a system-assigned id, your idempotenceKey, the body, and a Map<String, String> of attributes. The body is “any arbitrary string — it is up to the enqueuer and consumer to agree on the format.” Misk does not impose JSON, protobuf, or anything else; you serialize and deserialize on both ends.
Enqueuing uses JobEnqueuer. It’s coroutine-first, with blocking and async escape hatches:
interface JobEnqueuer {
suspend fun enqueue(
queueName: QueueName,
body: String,
idempotencyKey: String? = null,
deliveryDelay: Duration? = Duration.ZERO,
attributes: Map<String, String> = emptyMap(),
)
fun enqueueBlocking(queueName: QueueName, body: String, /* …same params… */)
fun enqueueAsync(queueName: QueueName, body: String, /* … */): CompletableFuture<Boolean>
}So from an action you’d write jobEnqueuer.enqueueBlocking(RECEIPT_QUEUE, receiptId) (or enqueue(...) from a suspending context). A QueueName is a trivial wrapper — data class QueueName(val value: String) — so define your queue names as constants and stop typo’ing them. There’s also batchEnqueue (max 10 messages per batch, the SQS limit) and an enqueueBuffered family that coalesces individual enqueues into batches client-side for high throughput — handy, but not where you should start.
Wiring the SQS backend
The interfaces above are abstract. The backend that makes them real is misk-aws2-sqs — the AWS SDK v2, coroutine-based SQS implementation, and the one to use for new services. Add the dependency:
dependencies {
implementation(project(":misk-aws2-sqs")) // or the published "com.squareup.misk:misk-aws2-sqs"
}Then install two modules: one that binds JobEnqueuer/JobConsumer to the SQS implementation, and one per queue you consume:
class SqsModule(private val config: SqsConfig) : KAbstractModule() {
override fun configure() {
install(SqsJobQueueModule(config))
install(SqsJobHandlerModule.create<SendReceiptHandler>(RECEIPT_QUEUE))
bind<DeadLetterQueueProvider>()
.toInstance(StaticDeadLetterQueueProvider("my-service-dlq"))
}
companion object {
val RECEIPT_QUEUE = QueueName("my-service-receipts")
}
}SqsJobHandlerModule.create<T>(queueName) is the whole registration: it map-binds your handler to the queue and stands up a SubscriptionService that starts pulling messages once the service is ready. Note that you register a handler per queue — a service has one subscription per queue, by design.
Config is YAML, validated into SqsConfig, with sensible defaults you can mostly leave alone:
aws_sqs:
all_queues:
parallelism: 1 # threads per queue
concurrency: 5 # coroutines per queue
max_number_of_messages: 10
wait_timeout: 20 # long-poll seconds
per_queue_overrides:
my-service-receipts:
concurrency: 10The two knobs that matter are parallelism (threads — raise it for blocking/CPU-bound handlers) and concurrency (coroutines — raise it for suspending, IO-bound handlers). region auto-populates from the AWS environment, so you rarely set it. Retry and dead-letter queues are managed for you (install_retry_queue defaults to true).
The transactional job queue, and the exactly-once-ish guarantee
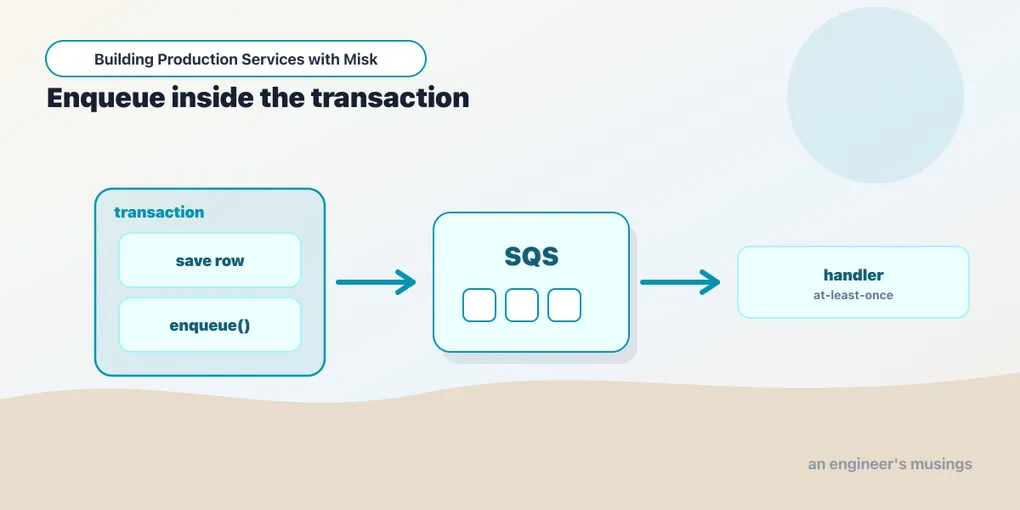
Here’s the scenario the at-least-once contract doesn’t cover. You take an order, write it to the database, and enqueue a “fulfil order” job. Two operations, two systems. If you enqueue then commit, the job can fire against an order that never persisted (the commit rolled back). If you commit then enqueue, the order persists but the enqueue can fail — and now you have a paid order that never ships. There is no ordering of “write to MySQL” and “RPC to SQS” that’s safe, because they’re not in the same transaction.
The classic fix is a spooling table: write the job into your own database, in the same transaction as the state change, and have a background process forward spooled rows to SQS. Commit covers both the order and the intent-to-enqueue atomically. Misk shipped exactly this as TransactionalJobQueue (in misk-transactional-jobqueue), keyed to a Hibernate Session and entity-group Gid so the job row lands on the same shard as your data:
fun enqueue(
session: Session,
gid: Gid<*, *>,
queueName: QueueName,
body: String,
idempotenceKey: String = UUID.randomUUID().toString(),
// …
)You’d call this inside the same transacter.transaction { ... } that writes your entity, and the job becomes part of the commit.
Now the honest part, and you should read the source before reaching for this. TransactionalJobQueue is @Deprecated in the current tree, and the deprecation message is unusually candid:
“This implementation is not strictly transactional since jobs are enqueued in a DB post commit hook. If the enqueueing operation fails, the DB record exists but no job is enqueued.”
So the spooling table was never fully closing the gap — it moved the enqueue into a post-commit hook, which can still fail after the commit lands. Misk’s prescribed replacement is the pattern the framework was pushing all along: use a plain JobQueue/JobEnqueuer, pass a meaningful idempotenceKey, persist that key in your handler, and check for it before doing the work. The deprecation’s own replaceWith says as much: ReplaceWith("JobQueue", "misk.jobqueue.JobQueue").
That’s the “exactly-once-ish” guarantee in practice. You don’t get distributed exactly-once delivery — nobody does, cheaply. You get effectively-once processing by making the side effect idempotent against a key you control:
override fun handleJob(job: Job): JobStatus = transacter.transaction { session ->
if (processedMarkers.exists(session, job.idempotenceKey)) return@transaction JobStatus.OK
doTheWork(job.body)
processedMarkers.insert(session, job.idempotenceKey) // same txn as the work
JobStatus.OK
}Deliver the job twice and the second delivery no-ops on the marker. The enqueue side stays a normal SQS call; correctness lives in the handler, in your database, under your transaction. It’s less magical than “transactional enqueue” sounded, and it’s the version that actually holds up.
Production notes and gotchas
- Write idempotent handlers — this is not optional. At-least-once means you will see duplicates in production, not “might.” Dedupe on
idempotenceKey(or a natural key from the body), ideally inside the same DB transaction as the side effect. - Don’t enqueue from inside a DB transaction. The plain
JobQueue.enqueuedoes an RPC to SQS, and its own docs warn against calling it while holding a transaction or other resources. Enqueue after the transaction, lean on the idempotency-key pattern for atomicity. deliveryDelaycaps at 15 minutes. SQS limits delivery delay to 900s, and Misk surfaces that limit directly. If you need “run this in three hours,” a job queue is the wrong tool — that’s Part 19’s territory.- Set a real dead-letter queue and watch it.
DEAD_LETTERand exhausted retries route to the DLQ. A DLQ nobody monitors is just a place where work goes to die silently; alarm on its depth. - Tune
visibility_timeoutagainst your slowest handler. If processing routinely outruns the visibility timeout, SQS re-delivers mid-flight and you get duplicate (and out-of-order) processing. Likewise, a non-zerochannel_capacitypre-fetches jobs and can blow the timeout before a handler even starts. - Use the fakes; don’t mock SQS.
misk-jobqueuetest fixtures shipFakeJobEnqueuer(andFakeJobHandlerModule), giving youpeekJobs(queue)to assert what got enqueued andhandleJobs()to drive your handler synchronously in a test. InstallFakeJobEnqueuerModule()and injectFakeJobEnqueuer. No LocalStack, no network.
One related-but-shakier neighbor: Misk also has misk-events for a pub/sub event-streaming style of asynchronous work, which is a different shape of problem than point-to-point job queues — treat it as adjacent, and don’t reach for it expecting the same maturity as the SQS job queue.
What’s next
Job queues handle work you trigger; some work triggers itself on a schedule. Running a cron job in a clustered service is its own puzzle — you want it to fire once across the fleet, not once per pod. In Part 19: Misk Cron: Cluster-Safe Scheduled Jobs we’ll wire periodic work that knows it’s running in more than one place.
Target keywords: misk job queue, misk sqs.
Comments