Misk SqlDelight, jOOQ & Vitess: Beyond Hibernate, and Sharding at Scale
Why misk sqldelight and jOOQ are the type-safe alternatives to Hibernate, plus misk vitess sharding for horizontal MySQL scale and the Vitess Gradle plugin.
Series: Building Production Services with Misk — Part 15 of 24
Part 13 sold you on Hibernate, and I stand by it for the common case. But Hibernate is not the only persistence story Misk ships, and pretending otherwise does you a disservice. Misk SqlDelight gives you compile-time-checked SQL that generates Kotlin; misk-jooq gives you a typed SQL DSL where the query is the code. And once your data outgrows a single MySQL box, none of that matters until you understand Misk Vitess sharding — horizontal scaling that Cash App runs in anger. This post covers all three. They’re separate tools that happen to share a chapter, so I’ll keep each one crisp.
SqlDelight in Misk (compile-time-checked SQL → Kotlin)
SqlDelight inverts the ORM premise. Instead of writing Kotlin and letting a framework emit SQL, you write SQL in .sq files and SqlDelight generates the Kotlin. Your queries are real SQL — checked at compile time against your schema. There is no dialect to fight, no @Entity graph to reason about, no lazy-loading footgun.
The SQL lives in .sq files, named queries and all. Here’s the real one from misk-sqldelight-testing:
getMovie:
SELECT * FROM movies WHERE id = :id;
createMovie:
INSERT INTO movies(id, title) VALUES (?, ?);The Gradle plugin (app.cash.sqldelight) turns that into a typed MoviesQueries class. Misk wires it up through the standard app.cash.sqldelight plugin, with the database derived straight from your migrations:
plugins {
id("org.jetbrains.kotlin.jvm")
id("app.cash.sqldelight")
}
sqldelight {
databases {
create("MoviesDatabase") {
packageName.set("misk.sqldelight.testing")
dialect(libs.sqldelightMysqlDialect)
srcDirs("src/main/sqldelight", "src/main/resources/migrations")
deriveSchemaFromMigrations.set(true)
verifyMigrations.set(true)
}
}
}That deriveSchemaFromMigrations.set(true) is the part to notice: SqlDelight reads the same migration files you wrote in Part 14, builds an in-memory schema from them, and validates every .sq query against it. Add a column, forget to update a query — the build fails. This is the whole pitch in one line.
What does Misk add on top of the SqlDelight runtime? Mostly retries. SqlDelight’s own Transacter has no notion of “this failed because of a deadlock, try again.” Misk’s RetryingTransacter wraps it:
abstract class RetryingTransacter @JvmOverloads constructor(
private val delegate: Transacter,
val options: TransacterOptions = TransacterOptions(),
dataSourceType: DataSourceType? = null,
) : Transacter {
override fun <R> transactionWithResult(
noEnclosing: Boolean,
bodyWithReturn: TransactionWithReturn<R>.() -> R,
): R = retryWithWork { delegate.transactionWithResult(noEnclosing, bodyWithReturn) }
// ...
}It classifies exceptions (SqlDelightExceptionClassifier), backs off exponentially, and retries the outermost transaction only — nested transactions don’t get their own retry loop, which is exactly right. You compose it onto your generated database in a Guice provider; the test module does precisely this, wrapping MoviesDatabase in an anonymous RetryingTransacter subclass. Note the seam: misk-sqldelight depends on misk-jdbc, so the underlying connection pool, health checks, and datasource config from Part 12 are all still yours.
jOOQ in Misk (typed SQL DSL)
jOOQ comes at the same problem from the other side. Instead of SQL in files, you write a fluent Kotlin DSL that reads like SQL and is type-checked by the Kotlin compiler:
ctx.select()
.from(AUTHOR.join(BOOK).on(BOOK.AUTHOR_ID.eq(AUTHOR.ID)))
.where(BOOK.NAME.like("sum of all%"))
.fetch()AUTHOR, BOOK, BOOK.AUTHOR_ID — those aren’t strings, they’re generated symbols. Typo a column and it won’t compile. The catch, and it’s a real one: jOOQ’s codegen needs a live schema to generate against. This is the chapter’s recurring theme. The misk-jooq README is blunt about it — you run your migrations into a throwaway database, point jOOQ’s code generator at it, and it emits the typed model. That’s what jooq-test-regenerate.sh does, and the README’s standing instruction is “run it every time you add a migration.” So jOOQ ties hard to Part 14: your migrations are the source of truth, and the generated DSL is a build artifact downstream of them. Forget to regenerate after a migration and your code drifts from your schema in a way the compiler can’t catch.
The Gradle side leans on the community nu.studer.gradle.jooq plugin plus Misk’s own schema-migrator plugin to stand up that scratch schema:
plugins {
alias(libs.plugins.miskSchemaMigrator)
alias(libs.plugins.jooq)
}Runtime wiring is a module. JooqModule takes a qualifier, a DataSourceClusterConfig, the codegen schema name, and an optional reader qualifier for replica reads:
install(JooqModule(
qualifier = JooqDBIdentifier::class,
dataSourceClusterConfig = datasourceConfig,
jooqCodeGenSchemaName = "jooq",
jooqTimestampRecordListenerOptions = JooqTimestampRecordListenerOptions(
install = true,
createdAtColumnName = "created_at",
updatedAtColumnName = "updated_at",
),
readerQualifier = JooqDBReadOnlyIdentifier::class,
))That JooqTimestampRecordListenerOptions is a genuinely nice touch — it auto-stamps created_at/updated_at on every record, so you stop hand-rolling that on insert.
For transactions, prefer the unified transacter. JooqUnifiedTransacterModule sits on top of JooqModule and gives you a misk.jooq.transacter.Transacter whose shape will feel familiar if you’ve used misk-hibernate or misk-jdbc:
interface Transacter {
val inTransaction: Boolean
fun <T> transaction(closure: (session: JooqSession) -> T): T
fun readOnly(): Transacter
fun <T> replicaRead(closure: (session: JooqSession) -> T): T
fun maxAttempts(maxAttempts: Int): Transacter
fun noRetries(): Transacter
fun isolationLevel(level: TransactionIsolationLevel): Transacter
}It’s a fluent, chainable config — transacter.readOnly().maxAttempts(3).transaction { session -> session.ctx.selectFrom(AUTHOR).fetch() }. The session.ctx is the jOOQ DSLContext — that’s where the DSL lives. replicaRead { } routes to the reader datasource if you configured one. And there’s a small guardrail worth stealing: inTransaction lets you check(!transacter.inTransaction) before making an RPC, so you never hold a database connection across a network call.
When to pick which (take a stance)
Here’s where I’ll commit to opinions rather than the usual “it depends” mush.
Default to Hibernate. For CRUD on an aggregate you own — entity graphs, the misk-hibernate transacter — it’s the path of least resistance and the most-trodden one in Misk. Most services never need anything else.
Reach for SqlDelight when SQL is the point. Reporting queries, read-heavy paths, anything where you’d rather see the actual SQL than reverse-engineer what an ORM emitted. The compile-time check against your migrations is the best property here — your queries can’t silently rot when the schema moves, because the build derives the schema from the migrations. If a teammate writes SQL by hand on the side anyway, formalize it in .sq files and get the safety for free.
Reach for jOOQ when you compose queries programmatically. Dynamic predicates, complex joins assembled at runtime, queries that branch on input — building those as strings is misery and building them in HQL is worse. jOOQ’s DSL shines exactly there, and the type safety is real. The tax is the codegen step and its hard dependency on regenerating after every migration. If your schema is stable and your queries are gnarly, pay it. If your schema churns daily, that regen friction will wear you down.
The honest summary: Hibernate for objects, SqlDelight for SQL you want to read, jOOQ for SQL you want to build. Don’t mix all three in one service just because you can — pick one per datasource and move on.
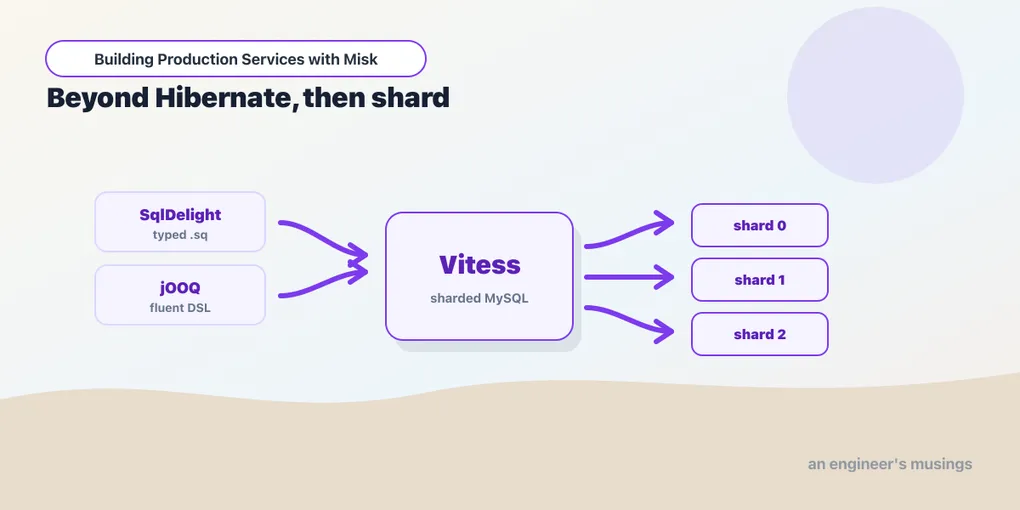
Vitess sharding (horizontal scaling)
Everything above assumes one MySQL. Vitess is what you run when one MySQL stops being enough. It’s a horizontally-sharding layer over MySQL that started at YouTube and now backs Slack, GitHub, Shopify, and — relevant here — Block, i.e. Cash App and Square. Block historically ran its own Vitess infrastructure and contributes upstream, which is why Misk’s Vitess support is battle-tested rather than aspirational: the README notes VitessTestDb runs over 100,000 tests in CI daily across Block’s apps.
The sharding model centers on the keyspace — Vitess’s logical database, which may be split across many physical shards. Your queries hit a vtgate (the proxy that routes to shards) instead of a raw MySQL port, and a vschema.json per keyspace tells Vitess how rows are sharded and which columns are lookup/sequence columns. From Misk’s side, the wiring is almost anticlimactic: it’s a datasource type. VITESS_MYSQL is a real DataSourceType in misk-jdbc, and you point your config at the vtgate:
data_source_clusters:
service_name:
writer:
type: VITESS_MYSQL
database: "@primary"
username: root
password: ""
port: 27003The @primary is Vitess routing syntax — “send writes to the primary tablet” — and 27003 is the default vtgate port. Because Vitess speaks the MySQL wire protocol, your SqlDelight, jOOQ, or Hibernate code mostly doesn’t know or care that it’s talking to a sharded cluster. Mostly — see gotchas.
For local development and tests, misk-vitess ships VitessTestDb, which spins a minified Vitess cluster in Docker via vttestserver:
val testDb = VitessTestDb()
testDb.run()It reads .sql schema files and vschema.json from a schema directory — default classpath:/vitess/schema, one subfolder per keyspace — applies them, and is ready on port 27003. It’s genuinely configurable: mysqlVersion, vitessImage, transactionIsolationLevel, enableScatters, lintSchema, in-memory tmpfs storage, and keepAlive to reuse the container across runs.
The Vitess Gradle plugin
Calling VitessTestDb().run() by hand in test setup is fine, but the cleaner path is the Vitess database Gradle plugin, id com.squareup.misk.vitess.vitess-database. It wraps VitessTestDb, registers a startVitessDatabase task, and you hang your tests off it:
plugins {
id("com.squareup.misk.vitess.vitess-database")
}
tasks.withType<Test>().configureEach {
dependsOn("startVitessDatabase")
}Need to tune it? The startVitessDatabase task is a StartVitessDatabaseTask, configurable in the usual Gradle way:
import misk.vitess.gradle.StartVitessDatabaseTask
val startVitessDatabase = tasks.named("startVitessDatabase", StartVitessDatabaseTask::class.java) {
containerName.set("my_vitess_db")
lintSchema.set(true)
mysqlVersion.set("8.0.42")
}This is the move for real services: tests run against a Vitess environment that mimics staging and production, so cross-shard queries and scatters behave in CI the way they will in prod. That’s the entire value proposition — catch the sharding-specific failures before they catch you.
Production notes & gotchas
- jOOQ codegen is only as fresh as your last regenerate. The generated model is a build artifact derived from your migrations. Add a migration, skip
jooq-test-regenerate.sh, and your typed DSL silently describes yesterday’s schema. Wire the regen into your migration workflow so it’s not a thing humans remember to do. - Don’t name your jOOQ migrations folder
migrations. Thejooq.jarships with its ownmigrationsdirectory of internal migrations, and on startup the service will find and try to run them. Name yoursdb-migrations(or anything else). This is documented but easy to trip over. - SqlDelight retries the outermost transaction only.
RetryingTransacterdeliberately doesn’t retry nested transactions. Good behavior, but it means a retryable failure deep in a nested call bubbles up to be retried at the top — design your transaction boundaries with that in mind, not around each inner call. - Vitess speaks MySQL until it doesn’t. The wire protocol is MySQL, so most queries port cleanly — but sharded clusters change the semantics of cross-shard joins, scatter queries, and anything assuming a single global ordering or a
LAST_INSERT_ID. Test those paths againstVitessTestDb, not a plain MySQL, or you’ll discover the differences in production. enableScattersneeds Vitess image version ≥ 20. Scatter queries (fan-out to all shards) are powerful and expensive. They’re on by default but gated on image version, and you generally want to minimize them in hot paths — a scatter is N shard round-trips dressed up as one query.- Highly-parallel CI can exhaust the Docker network. Every
VitessTestDbdefaults to the sharedvitess-networkbridge. Run hundreds in parallel against one daemon and you can drain that network’s IPv4 pool; set a uniquedockerNetworkNameper instance if you hit it. Block’s own docs call this out, which tells you it’s been hit for real.
What’s next
Three persistence options down, and we still haven’t left the database. Sometimes the fastest query is the one you don’t run — in Part 16: Misk Redis & Caching we’ll put a cache in front of all of this, and talk about when caching saves you and when it just adds a second source of truth to keep wrong.
Target keywords: misk sqldelight, misk vitess sharding.
Comments