Misk JDBC & Data Sources: Connection Pooling and Read/Write Splitting
How misk jdbc wires a real database: misk datasource config, Hikari connection pooling, read/write splitting via reader/writer clusters, and the JDBC-layer Transacter.
Series: Building Production Services with Misk — Part 12 of 24
So far this series has been about the shape of a service: actions, interceptors, auth, config. Eventually, though, a real service has to talk to a real database, and that’s where the comfortable abstractions stop and the operational realities start. You need a connection pool sized for your traffic, sensible timeouts, probably a read replica to offload queries from the primary, and a transaction boundary that doesn’t leak connections when something throws. Misk JDBC is the module that handles all of that — misk-jdbc gives you a configured javax.sql.DataSource, a Hikari pool wired up underneath it, and a Transacter that owns the begin/commit/rollback dance so you don’t have to. Let’s connect a database.
What a misk datasource actually is
A misk datasource is a javax.sql.DataSource that Misk builds for you from config and binds into Guice under a qualifier. You never new a connection pool, never hand-roll a JDBC URL, never call DriverManager. You write a YAML block describing the database, install a module pointing at it, and you get an injectable DataSource plus a Transacter for running transactions against it.
The config is split into three nested types, all verifiable in DataSourceConfig.kt:
DataSourceConfig— one physical database: type, host, port, credentials, pool size, timeouts, migrations.DataSourceClusterConfig(val writer: DataSourceConfig, val reader: DataSourceConfig?)— awriterand an optionalreader. This is the read/write split, right in the type.DataSourceClustersConfig— aLinkedHashMap<String, DataSourceClusterConfig>(and a MiskConfig), so your YAML can declare several named clusters.
The supported database types are a closed enum, not a string — DataSourceType is MYSQL, POSTGRESQL, COCKROACHDB, TIDB, VITESS_MYSQL, and HSQLDB. That last one is the in-memory store you’ll lean on in tests; everything else is a real server. There’s no OTHER escape hatch, which is the right call: Misk knows the dialect and driver for each, and an unsupported database is a compile error rather than a runtime surprise.
Setup and wiring
Start with the Gradle coordinate. Misk publishes to Maven Central under com.squareup.misk, and the JDBC module is its own artifact:
dependencies {
implementation("com.squareup.misk:misk-jdbc")
// For tests, the in-memory datasource and schema-migrator helpers:
testImplementation(testFixtures("com.squareup.misk:misk-jdbc"))
}Next, the config. A datasource lives under a named cluster, with a writer: block (and optionally a reader:). Here’s the exemplar’s, straight from exemplar-common.yaml:
data_source_clusters:
exemplar-001:
writer:
type: MYSQL
username: root
password: ""
database: exemplar_testing
migrations_resource: "classpath:/migrations"The YAML keys map one-to-one onto DataSourceConfig fields, so anything in that data class is fair game — fixed_pool_size, connection_timeout, query_timeout, connection_max_lifetime, and so on. We’ll come back to the ones that bite.
To surface this in your config, add the cluster map to your service’s config class:
data class ExemplarConfig(
val data_source_clusters: DataSourceClustersConfig,
// ...other config...
) : ConfigThen install a JdbcModule, which binds the datasource and Transacter under a qualifier annotation you define. The qualifier is how you tell apart multiple databases in one service; each gets its own annotation:
@Qualifier
@Target(AnnotationTarget.FIELD, AnnotationTarget.FUNCTION)
annotation class Movies
class MoviesDatabaseModule(private val config: DataSourceClustersConfig) : KAbstractModule() {
override fun configure() {
val cluster = config["exemplar-001"]!!
install(JdbcModule(Movies::class, cluster.writer))
}
}That single install does a lot. Reading JdbcModule.configure(), it binds a qualified DataSource and DataSourceConfig, registers the DataSourceService (the thing that opens the pool), wires a PingDatabaseService health check, installs the SchemaMigratorService so your migrations run on boot, and binds a Transacter for the qualifier:
bind(keyOf<Transacter>(qualifier)).toProvider { RealTransacter(dataSourceServiceProvider.get(), config) }Now @Movies Transacter and @Movies DataSource are injectable anywhere.
Worked example
Here’s a DAO running a transaction over the JDBC-layer Transacter. Note the qualifier on the injected dependency — that’s what binds this DAO to the exemplar-001 cluster:
@Singleton
class MovieDao @Inject constructor(
@Movies private val transacter: Transacter,
) {
fun addMovie(name: String, releaseYear: Int): Long =
transacter.transactionWithSession { session ->
session.useConnection { connection ->
connection.prepareStatement(
"INSERT INTO movies (name, release_year) VALUES (?, ?)"
).use { stmt ->
stmt.setString(1, name)
stmt.setInt(2, releaseYear)
stmt.executeUpdate()
}
connection.prepareStatement("SELECT LAST_INSERT_ID()").use { stmt ->
stmt.executeQuery().use { rs -> rs.next(); rs.getLong(1) }
}
}
}
}transactionWithSession opens a transaction, hands you a JDBCSession, and commits when the block returns normally — or rolls back if it throws. The session.useConnection { connection -> ... } gives you the raw java.sql.Connection. Yes, this is hand-written SQL with PreparedStatement. That’s the deal at the JDBC layer: Misk manages the connection and transaction lifecycle, you manage the SQL. If hand-rolling SQL makes you wince, that’s the cue for Part 13 — but this layer is genuinely useful when you want full control or you’re not on a JVM ORM at all.
Going deeper
Connection pooling via Hikari
Misk doesn’t write its own pool. It uses HikariCP, the same one everyone uses, because it’s fast and boring in the best way. RealTransacter’s internals even rely on a Hikari guarantee, with the comment to prove it:
// We are using Hikari, which will automatically roll back incomplete transactions.
// This means there's actually no need to wrap the transaction in a try clause to
// do rollback on exceptionThe pool is sized and tuned through the same DataSourceConfig fields you saw in YAML. The defaults from the data class are worth knowing because they’re the values you ship with if you say nothing:
fixed_pool_size = 10— pool size. The default is small; size it for your concurrency.connection_timeout = 10s— how long a caller waits for a connection before giving up.query_timeout = 1m— socket timeout, folded into the JDBC URL.connection_max_lifetime = 1m— how long a connection lives before recycling.validation_timeout = 3s— connection validation budget.
Misk also auto-exports Hikari’s Prometheus metrics — hikaricp_connection_timeout_total, hikaricp_connection_acquired_nanos, hikaricp_connection_usage_millis, hikaricp_connection_creation_millis — labelled by pool name. When connection acquisition starts timing out, those are the first graphs you’ll stare at.
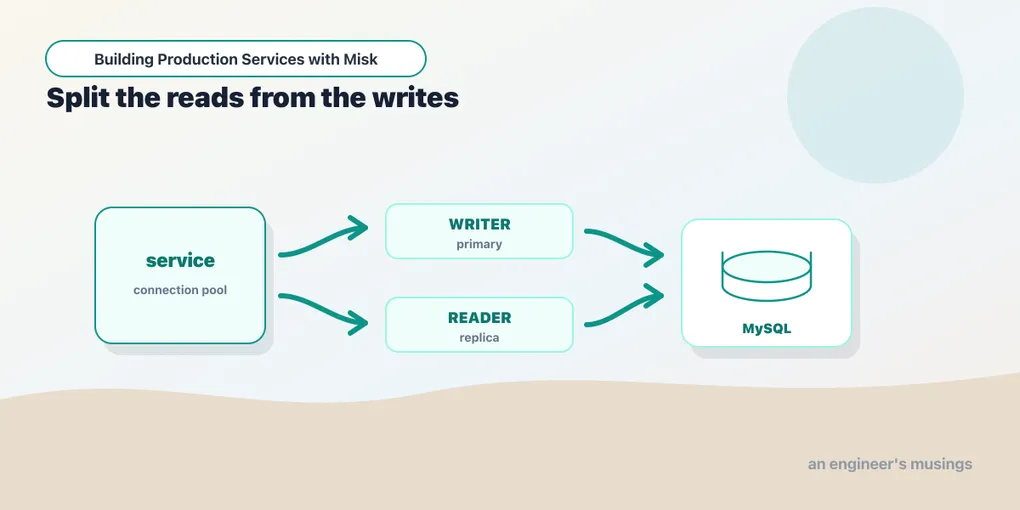
Read/write splitting
The read/write split is built into the cluster type: DataSourceClusterConfig(writer, reader?). In YAML it’s a sibling reader: block:
data_source_clusters:
movies-001:
writer:
type: MYSQL
host: movies-primary.internal
database: movies
reader:
type: MYSQL
host: movies-replica.internal
database: moviesJdbcModule has a constructor that takes both — JdbcModule(qualifier, writerConfig, readerQualifier, readerConfig) — and it binds the reader datasource under its own qualifier:
install(
JdbcModule(
qualifier = Movies::class,
config = cluster.writer,
readerQualifier = MoviesReader::class,
readerConfig = cluster.reader,
)
)This is honest about what read/write splitting actually is: two pools, two qualifiers. You inject @Movies Transacter to write and @MoviesReader Transacter to read from the replica. There’s no magic router silently sending your SELECTs elsewhere — you choose the qualifier at the injection site, which means the read/replica decision is explicit and reviewable, not a config flag that quietly changes correctness. One sharp edge: JdbcModule won’t let you set a readerQualifier without a readerConfig — it checks that the reader is configured and fails fast at startup if you forgot the YAML.
The Transacter at the JDBC layer
The Transacter interface is small and worth reading in full because the names matter:
interface Transacter {
val inTransaction: Boolean
fun <T> transactionWithSession(work: (session: JDBCSession) -> T): T
fun retries(maxAttempts: Int): Transacter
fun noRetries(): Transacter
// transaction(work: (Connection) -> T) exists but is @Deprecated
}A few things fall out of this:
- Use
transactionWithSession, nottransaction. The oldtransaction { connection -> }form is@Deprecatedin the source, withreplaceWith = "transactionWithSession(work)". The session form gives you pre/post-commit and rollback hooks —session.onPostCommit { ... },session.onRollback { ... }— which the bare-connection form can’t. - Retries are first-class and on by default.
RealTransacterwraps every transaction in an exponential-backoff retry loop, retrying up to three attempts by default on exceptions anExceptionClassifierdeems retryable (deadlocks, transient connection failures). Want different behavior?transacter.retries(5)ortransacter.noRetries()return a newTransacterwith that policy — they don’t mutate the shared one. - Nesting is an error, not a no-op.
transactionInternaldoescheck(!transacting.get()) { "The current thread is already in a transaction" }. Open a transaction inside a transaction on the same thread and you get an exception, not silent reentrancy. Treat the transaction boundary as a thing you cross exactly once.
This is the JDBC-layer Transacter: it speaks java.sql.Connection and you write SQL by hand. Misk has a second Transacter — the Hibernate one in misk-hibernate — that speaks entities and sessions instead of connections and SQL. Same name, same retry/transaction philosophy, completely different ergonomics. That’s Part 13. For now, just know that “the Transacter” is overloaded, and which one you mean depends on which module you installed.
Production notes & gotchas
- The default pool of 10 is a starting line, not an answer.
fixed_pool_size = 10is conservative. Under real concurrency you’ll see callers blocking on connection acquisition long before the database is the bottleneck; watchhikaricp_connection_timeout_totaland size up. More pools across more instances also means more total connections hitting the DB; the math is yours to do. readerwithoutreaderQualifierdoes nothing — and the reverse fails loudly. Areader:block in YAML is inert unless you actually passreaderQualifier+readerConfigtoJdbcModule. Conversely, areaderQualifierwith no reader config fails the startupcheck. Wire both halves or neither.- Reading from the replica is your decision, and replicas lag. Because the split is two qualifiers,
@MoviesReaderreads can return stale data, because replication isn’t instant. Don’t read-after-write through the reader and expect to see your own write. Route anything that needs read-your-writes consistency through the writer. query_timeoutdefaults to one minute and becomes the socket timeout. It’s nullable, but the default folds a 60ssocketTimeoutinto the JDBC URL. A genuinely long query will be killed at the socket. Tune per datasource rather than discovering this in an incident.HSQLDBis for tests, full stop. It maps to an in-memory database (jdbc:hsqldb:mem:...) and uses the H2 dialect under the hood. Great for fast tests viaJdbcTestingModule; never a production type.@Redactkeeps passwords out of logs — don’t undo it.password,trust_certificate_key_store_password, and the client cert password are all annotated@RedactonDataSourceConfig, so Misk’s config dump won’t leak them. If you add your own credential field, redact it too.COCKROACHDBandTIDBdon’t do replica reads the Vitess way.asReplica()only synthesizes a replica config forVITESS_MYSQL; for Cockroach/TiDB it returns the same config (they handle reads differently). Don’t assumereadersemantics are identical across everyDataSourceType.
What’s next
This post stayed at the JDBC layer on purpose: connections, pools, and hand-written SQL inside a transactionWithSession. It’s the right tool when you want full control, but most services would rather think in entities than PreparedStatements. In Part 13: Misk Hibernate and the Transacter we’ll meet the other Transacter — the Hibernate one — and see how Misk layers an ORM, typed queries, and entity sessions on top of everything we just wired.
Target keywords: misk jdbc, misk datasource.
Comments